Skip to the content.
AWS Solutions Architect – Professional
EMR - Elastic Map Reduce
MapReduce 101
- Is a framework designed to allow processing huge amount of data in a parallel, distributed way
- Data Analysis Architecture: huge scale, parallel processing
- MapReduce has two main phases: map and reduce
- It also has to optional phases: combine and partition
- At high level the process of map reduce is the following:
- Data is separated into splits
- Each split can be assigned to a mapper
- The mapper perform the operation at scale
- The data is recombined after the operation is completed
- HDFS (Hadoop File System):
- Traditionally stored across multiple data nodes
- Highly fault-tolerant - data is replicated between nodes
- Named Nodes: provide the namespace for the file system and controls access to HDFS
- Block: a segment of data in HDFS, generally 64 MB
Amazon EMR Architecture
- Is a managed implementation of Apache Hadoop, which is a framework for handling big data workloads
- EMR includes other elements such as Spark, HBase, Presto, Flink, Hive, Pig
- EMR can be operated long term, or we can provision ad-hoc (transient) clusters for short term workloads
- EMR runs in one AZ only within a VPC using EC2 for compute
- It can use spot instances, instance fleets, reserved and on-demand instances as well
- EMR is used for big data processing, manipulation, analytics, indexing, transformation, etc.
- EMR architecture:
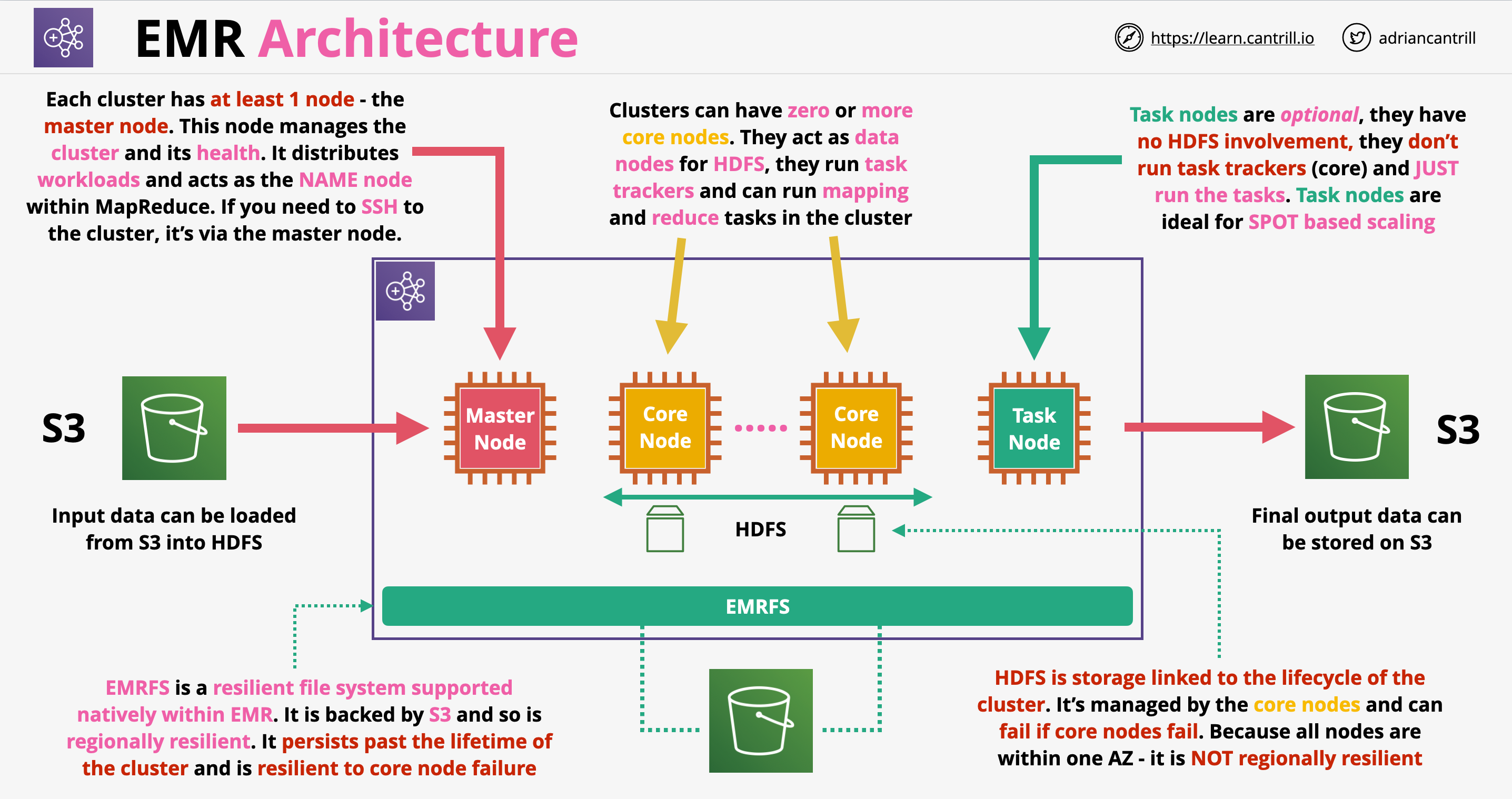
- Historically we could have only one master node, nowadays we can have 3 master nodes
- Core nodes: they are used for tracking task, we don’t want to destroy these nodes
- Core nodes also managed to HDFS storage for the cluster. The lifetime of HDFS is linked to the lifetime of the core nodes/cluster
- Task nodes: used to only run tasks. If they are terminated, the HDFS storage is not affected. Ideally we use spot instances for task nodes
- EMRFS: file system backed by S3, can persist beyond the lifetime of the cluster. Offers lower performance than HDFS, which is based on local volumes